
Challenge Yourself with the World's Most Realistic SPLK-1003 Test.
In this source definition the MAX_TIMESTAMP_LOOKHEAD is missing. Which value would fit best?
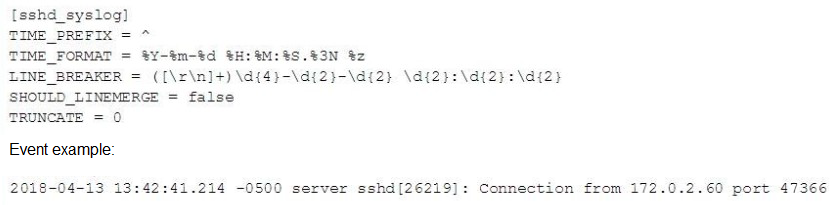
A. MAX_TIMESTAMP_L0CKAHEAD = 5
B. MAX_TIMESTAMP_LOOKAHEAD - 10
C. MAX_TIMESTAMF_LOOKHEAD = 20
D. MAX TIMESTAMP LOOKAHEAD - 30
Explanation:
MAX_TIMESTAMP_LOOKAHEAD controls how many characters Splunk reads after TIME_PREFIX to attempt to extract the timestamp using the specified TIME_FORMAT.
🔍 Analysis of the Sample Event:
2018-04-13 13:42:41.214 -0500 server sshd[26219]: Connection from 172.0.2.60 port 47366
From the beginning of the line, the timestamp portion is:
2018-04-13 13:42:41.214 -0500
Count the characters:
2018-04-13 → 10 characters
space → 1
13:42:41.214 → 12 characters
space → 1
-0500 → 5 characters
Total: 29 characters
🔧 Why 20 Is a Good Fit:
While the full timestamp is 29 characters, MAX_TIMESTAMP_LOOKAHEAD doesn't always need to cover the entire line—it just needs to capture enough characters after TIME_PREFIX to match TIME_FORMAT.
In this case:
The TIME_PREFIX = ^ (start of line)
TIME_FORMAT = %Y-%m-%d %H:%M:%S.%3N %z — this format roughly consumes 29 characters
So 20 is a commonly safe choice in default configs when the format is known and timestamp is early in the line. However, to fully and safely parse this specific format, a better value might actually be closer to 30.
🧠 Best Practice:
If timestamp is long or positioned later in the line, increase MAX_TIMESTAMP_LOOKAHEAD.
Default value is 128, but if you're optimizing for performance or managing edge parsing, you might tune it down.
📘 Splunk Docs Reference:
MAX_TIMESTAMP_LOOKAHEAD: "Specifies how many characters forward from TIME_PREFIX Splunk software should search for a timestamp."
Source: props.conf spec - Splunk Docs
❌ Why the others are incorrect:
A. 5 — Too short; won't capture even the date.
B. 10 — Still too short.
D. 30 — Technically valid, but more than necessary unless timestamp is deeper in the event. (Would still work, but not the best minimal value.)
What is the correct example to redact a plain-text password from raw events?
A. in props.conf:
[identity]
REGEX-redact_pw = s/password=([^,|/s]+)/ ####REACTED####/g
B. in props.conf:
[identity]
SEDCMD-redact_pw = s/password=([^,|/s]+)/ ####REACTED####/g
C. in transforms.conf:
[identity]
SEDCMD-redact_pw = s/password=([^,|/s]+)/ ####REACTED####/g
D. in transforms.conf:
[identity]
REGEX-redact_pw = s/password=([^,|/s]+)/ ####REACTED####/g
Explanation:
To redact sensitive data (like passwords) from raw events in Splunk, you use SEDCMD in props.conf. Here’s why:
SEDCMD vs. REGEX:
SEDCMD (Stream Editor Command) is designed for in-place text substitution in raw events.
REGEX is used for field extraction or filtering, not direct redaction.
Correct File (props.conf):
Redaction rules for raw data belong in props.conf, not transforms.conf.
transforms.conf is for field transformations, not modifying raw events.
Syntax:
The format is SEDCMD-
Example: s/password=([^,|\s]+)/ ####REDACTED####/g replaces passwords like password=secret with ####REDACTED####.
Why Not the Other Options?
A: Uses REGEX-redact_pw, which is invalid for redacting raw events.
C/D: Incorrectly place the rule in transforms.conf, which won’t modify raw events.
Reference:
Splunk Docs: Mask sensitive data with SEDCMD
Which of the following is the use case for the deployment server feature of Splunk?
A. Managing distributed workloads in a Splunk environment
B. Automating upgrades of Splunk forwarder installations on endpoints
C. Orchestrating the operations and scale of a containerized Splunk deployment
D. Updating configuration and distributing apps to processing components, primarily forwarders.
Explanation:
The Deployment Server in Splunk is specifically designed for:
Centralized management of configurations and apps for forwarders (Universal Forwarders, Heavy Forwarders).
Pushing updates (e.g., inputs.conf, props.conf, custom apps) to forwarders without manual intervention.
Grouping forwarders into server classes for targeted deployments.
Why Not the Other Options?
A: Distributed workloads are managed by indexers/search heads, not the Deployment Server.
B: While the Deployment Server can facilitate upgrades, its primary role is configuration/app distribution, not upgrade automation (tools like DSC or OS package managers handle upgrades).
C: Container orchestration (e.g., Splunk on Kubernetes) uses tools like Splunk Operator, not the Deployment Server.
Key Use Cases:
Deploying input configurations (e.g., monitoring files, network ports).
Distributing parsing rules (e.g., props.conf, transforms.conf).
Managing forwarder-side apps (e.g., custom scripts, filters).
Reference:
Splunk Docs: About the Deployment Server
For single line event sourcetypes. it is most efficient to set SHOULD_linemerge to what value?
A. True
B. False
C.
D. Newline Character
Explanation:
For single-line event sourcetypes, the most efficient and recommended setting is:
SHOULD_LINEMERGE = false
This setting tells Splunk to treat each line as a separate event, which is optimal for logs where each event is contained on a single line (like Apache access logs, syslog, firewalls, etc.).
🔍 Why this is important:
When SHOULD_LINEMERGE = true, Splunk tries to combine multiple lines into a single event based on patterns. This is useful for multi-line events (e.g., Java stack traces), but it:
Consumes more resources (CPU and memory)
Slows down indexing
Setting it to false improves indexing performance for single-line logs.
📘 Splunk Docs Reference:
"SHOULD_LINEMERGE = false tells Splunk to treat each new line as a new event, which is the most efficient setting for single-line logs."
Source: Splunk props.conf documentation
❌ Why the other options are incorrect:
A. True — Used for multi-line events; not efficient for single-line data.
C.
D. Newline Character — Not a valid value for this setting.
Which of the following types of data count against the license daily quota?
A. Replicated data
B. splunkd logs
C. Summary index data
D. Windows internal logs
Explanation:
Splunk licensing is based on the amount of data indexed per day, and this includes most types of data ingested through inputs, including Windows internal logs.
Here’s how each option applies:
✔️ D. Windows internal logs
Count against the license if collected via inputs like WinEventLog://, perfmon://, or monitor:// of .evt/.evtx files.
Treated just like any other incoming data that gets parsed and indexed.
❌ A. Replicated data
Does NOT count against the license.
Applies to index replication in indexer clustering; only the original copy of the data counts, not the replicated copies.
❌ B. splunkd logs
Do NOT count toward license usage.
These are internal logs written by Splunk for its own operations (e.g., $SPLUNK_HOME/var/log/splunk/splunkd.log).
❌ C. Summary index data
Does NOT count against the license.
Summary indexing is used to store pre-computed search results (e.g., for accelerated reports).
Since it’s derived data already indexed once, it’s excluded from license calculations.
📘 Splunk Docs Reference:
“The license volume is based on the amount of original data that you index per day. This does not include replicated data in indexer clusters, or data written to summary indexes.”
Source: About license violations - Splunk Docs
Which of the following indexes come pre-configured with Splunk Enterprise? (select all that apply)
A. _license
B. _lnternal
C. _external
D. _thefishbucket
Explanation:
Splunk Enterprise comes with several pre-configured indexes for system and operational data.
Here’s a breakdown:
_license (A):
Stores Splunk license usage and violation data.
Critical for monitoring license compliance.
_internal (B):
Contains Splunk’s internal logs (e.g., indexer, search head, and deployment server activity).
Used for troubleshooting Splunk itself.
_thefishbucket (D):
Tracks file checksums for file-based inputs (prevents re-indexing the same data).
Essential for monitoring file ingestion.
Why Not _external (C)?
_external is not a default index. It might be confused with _external_alerts (a custom index for alert actions) or user-created indexes for external data.
Key Notes:
Default indexes are prefixed with an underscore (_).
Other pre-configured indexes include _audit (audit logs) and _introspection (performance metrics).
Reference:
Splunk Docs: Default indexes
Which forwarder type can parse data prior to forwarding?
A. Universal forwarder
B. Heaviest forwarder
C. Hyper forwarder
D. Heavy forwarder
Explanation:
Heavy Forwarder:
Can parse, filter, and transform data before forwarding it (e.g., using props.conf, transforms.conf).
Supports Splunk processing pipelines (like an indexer but without storing data).
Requires a forwarder license.
Universal Forwarder (A):
Forwards raw data only (no parsing or processing).
Lightweight and license-free.
Heaviest Forwarder (B) & Hyper Forwarder (C):
These are not real Splunk components (distractors).
Key Use Case for Heavy Forwarder:
Pre-process data at the edge (e.g., filter sensitive fields, apply sourcetypes) to reduce load on indexers.
Reference:
Splunk Docs: Forwarder types
What conf file needs to be edited to set up distributed search groups?
A. props.conf
B. search.conf
C. distsearch.conf
D. distibutedsearch.conf
Explanation:
To configure distributed search groups in Splunk, you must edit the distsearch.conf file.
This file is used to define:
Search peers (indexers that a search head can send search requests to)
Search groups (grouping of search peers)
Authentication settings between search head and indexers
📘 Common settings in distsearch.conf:
[distributedSearch]
servers = indexer1:8089, indexer2:8089
[distributedSearch:group1]
servers = indexer1:8089, indexer2:8089
File location: $SPLUNK_HOME/etc/system/local/distsearch.conf (or app-specific directory)
❌ Why the other options are incorrect:
A. props.conf – Used for data parsing and event handling, not related to search peer configuration.
B. search.conf – Used for search-related behaviors and UI defaults, not for distributed configuration.
D. distibutedsearch.conf – This is a misspelled/invalid file name.
📘 Splunk Docs Reference:
“Use distsearch.conf to configure distributed search. You can add search peers, configure groups of search peers, and set connection/authentication settings.”
Ref: distsearch.conf spec - Splunk Docs
Which of the following enables compression for universal forwarders in outputs. conf ?

A. Option A
B. Option B
C. Option C
D. Option D
Explanation
# Compression
#
# This example sends compressed events to the remote indexer.
# NOTE: Compression can be enabled TCP or SSL outputs only.
# The receiver input port should also have compression enabled.
[tcpout]
server = splunkServer.example.com:4433
compressed = true
In case of a conflict between a whitelist and a blacklist input setting, which one is used?
A. Blacklist
B. Whitelist
C. They cancel each other out.
D. Whichever is entered into the configuration first.
Explanation:
In Splunk, when there’s a conflict between whitelist and blacklist settings for inputs (e.g., in inputs.conf), the blacklist takes precedence. Here’s why:
Blacklist Overrides Whitelist:
If a file or path matches both the whitelist and blacklist, Splunk excludes it (blacklist wins).
Example:
text
[monitor:///var/log/*.log]
whitelist = \.log$
blacklist = security\.log
Even if security.log matches the whitelist, it’s ignored because it’s blacklisted.
Security/Performance Rationale:
Blacklists are prioritized to ensure safe data ingestion (e.g., excluding sensitive files).
Avoids accidentally indexing unwanted data due to overly broad whitelists.
Why Not Other Options?
B (Whitelist): Incorrect—blacklist has higher priority.
C (Cancel out): Splunk doesn’t "neutralize" conflicts; blacklist wins.
D (Order of entry): Irrelevant—Splunk evaluates rules logically, not chronologically.
Reference:
Ref: Splunk Docs: inputs.conf whitelist/blacklist behavior
| Page 4 out of 21 Pages |
| Splunk SPLK-1003 Dumps Home | Previous |
Contact Us - Privacy Policy ... Copyright © - All Rights Reserved